
I am a first-year Master’s student at the School of Electronic and Computer Engineering, Peking University , advised by Prof. Daquan Zhou and Prof. Yonghong Tian . I received my B.E. degree from the University of Chinese Academy of Sciences (UCAS) in 2025, where I was awarded as an Outstanding Graduate.
My current research interest centers on world-action models (WAM) for embodied intelligence. I am actively seeking collaboration and internship opportunities — feel free to contact me.
News
- 2026.06: 🎉🎉 One paper is accepted by ECCV 2026.
- 2025.05: 🎉🎉 I am selected as an Outstanding Graduate of Beijing, with my undergraduate thesis named an Outstanding Graduation Paper of UCAS.
- 2024.11: 🎉🎉 I win the China National Scholarship and First-Level Scholarship of UCAS!
- 2024.07: 🎉🎉 One paper is accepted by ECCV 2024.
Publications
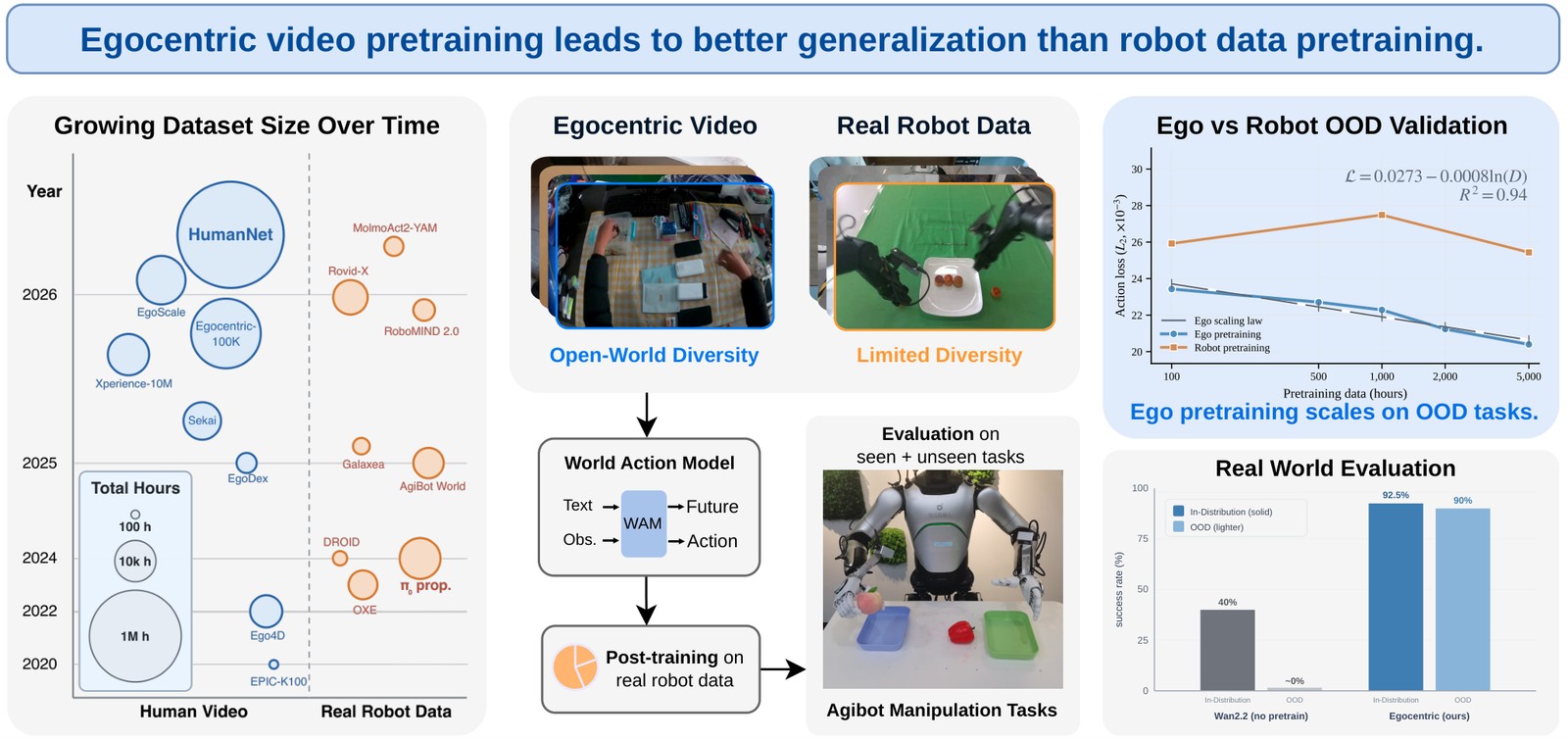
HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
Juncheng Ma*, Jianxin Bi*, Yufan Deng, Xuanran Zhai, Kewei Zhang, Ye Huang, Bo Liang, Shukai Gong, Jiankai Tu, Xiaotian Tang, Jiaxin Li, Kaiqi Chen, Duomin Wang, Yuqi Wang, Bingyi Kang, Eric Huang, Zhiyang Dou, Zhen Dong, Enze Xie, Wojciech Matusik, Tat-Seng Chua, Daquan Zhou
(* Equal contribution)
Technical Report | arXiv | Code
With a carefully designed filtering and labeling pipeline, we show that egocentric human video is a scalable pretraining source for embodied foundation models that surpasses real-robot data, especially in out-of-distribution generalization.
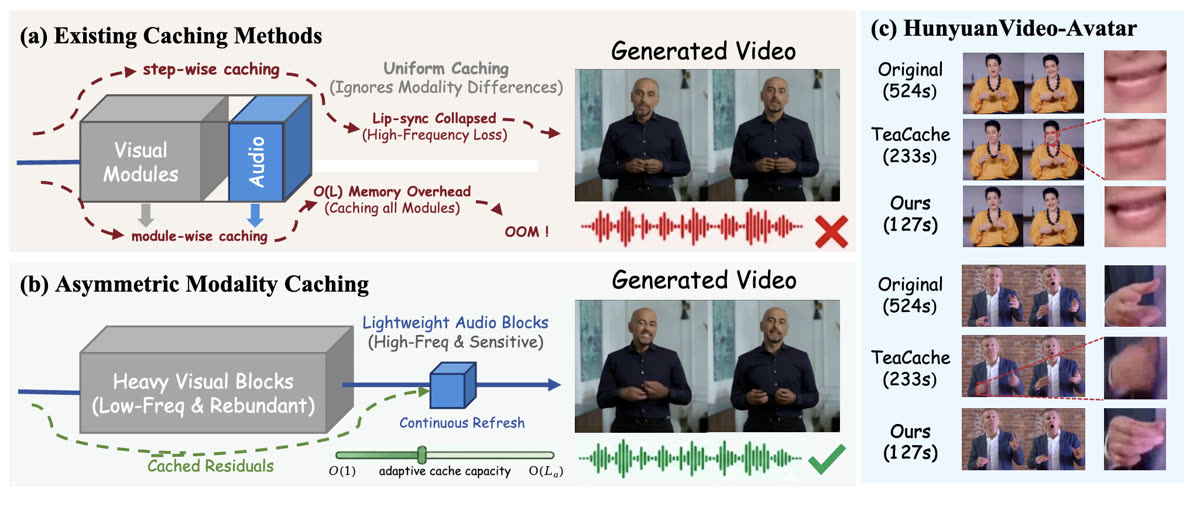
SyncCache: Exploiting Asymmetric Dynamics for Fast Audio-Driven Portrait Animation
Juncheng Ma, Yuxuan Du, Yanan SUN, Zhening Xing, Changlin Li, Zhenyu Tang, Bo Li, Peng-Tao Jiang, Li Yuan, Daquan Zhou†, Yonghong Tian†
ECCV 2026
We propose SyncCache, a training-free caching acceleration method tailored for DiT-based portrait animation that exploits spatial and modality asymmetries, delivering up to 4.12× acceleration on HunyuanVideo-Avatar and 3.75× on Wan-S2V with near-lossless visual fidelity and precise audio alignment.
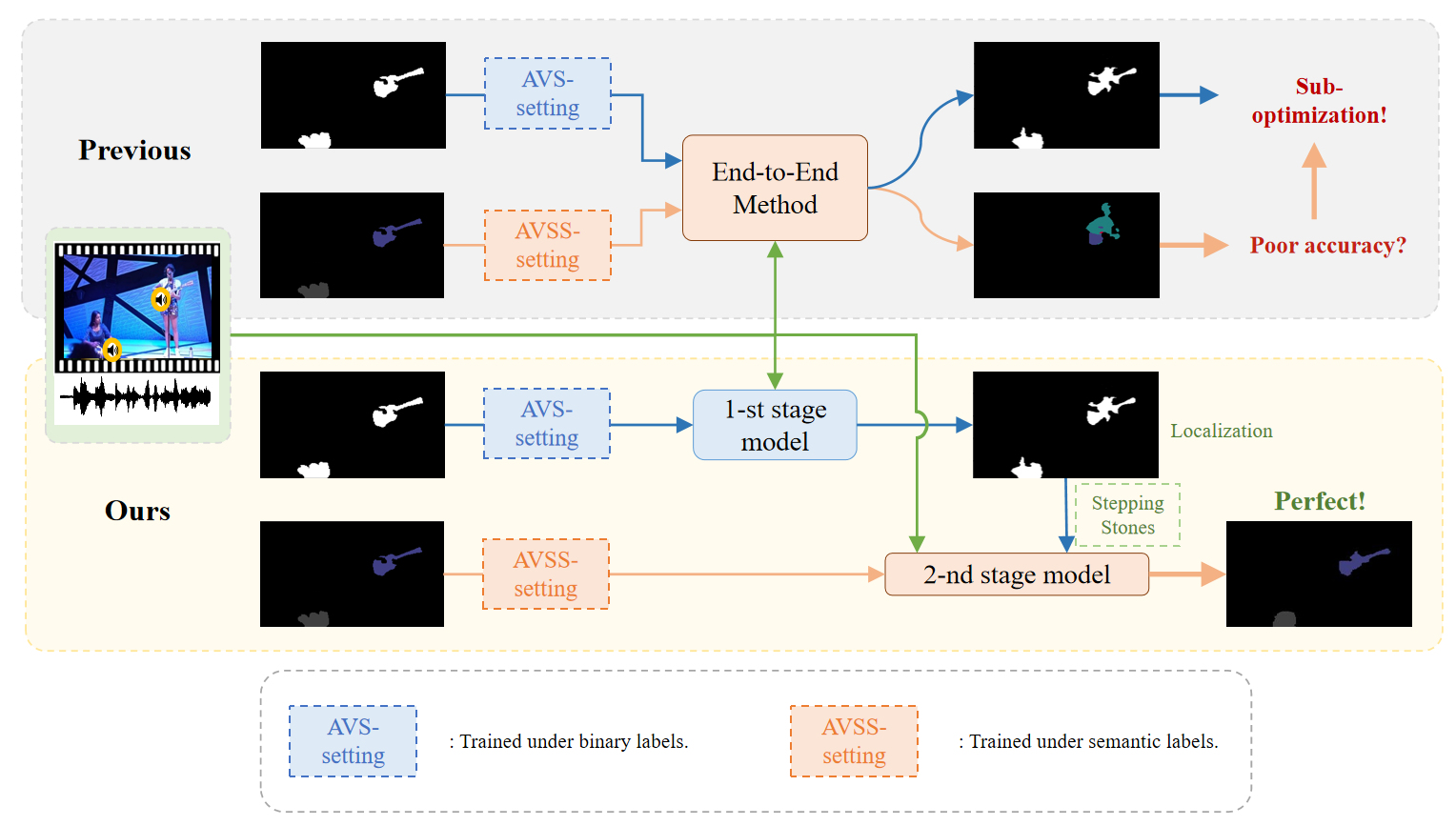
Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation
Juncheng Ma, Peiwen Sun, Yaoting Wang, Di Hu
ECCV 2024 | arXiv | Code | Project | PDF | Supplementary
Rethink audio-visual semantic segmentatoin from a new perspective, with a progressive two-stage training strategy proposed to enhance the capability of audio-visual alignment .
Experiences

Research Intern, Shanghai AI Laboratory, Shanghai, China, 2024.7-2024.11
Research on video generation especially audio-driven portrait animation.
Supervised by Dr. Yanan Sun and Dr. Yanhong Zeng

Visiting Student, Renmin University of China, Beijing, China, 2023.10-2024.3
Research on multimodal learning especially audio-visual segmentation, aiming to segment sound sources within a video according to its corresponding audio.
One paper Stepping-Stones is accepted by ECCV2024.
Supervised by Prof. Di Hu
Honors and Awards
- 2025, Outstanding Graduation Paper of UCAS.
- 2025, Outstanding Graduate of Beijing.
- 2024, China National Scholarship.
- 2024, First-Level Scholarship of UCAS.
Educations
- 2025.09 - present, Master, Peking University.
- 2021.09 - 2025.6, Undergraduate, University of Chinese Academy of Sciences.